I can’t take credit for that line; I stole^H^H^H^H^Hborrowed it from someone who I can’t remember.
I’ve been having some fun working with recursion, XPathNavigators, and interesting XPath queries, so I thought I’d share some tidbits I worked through.
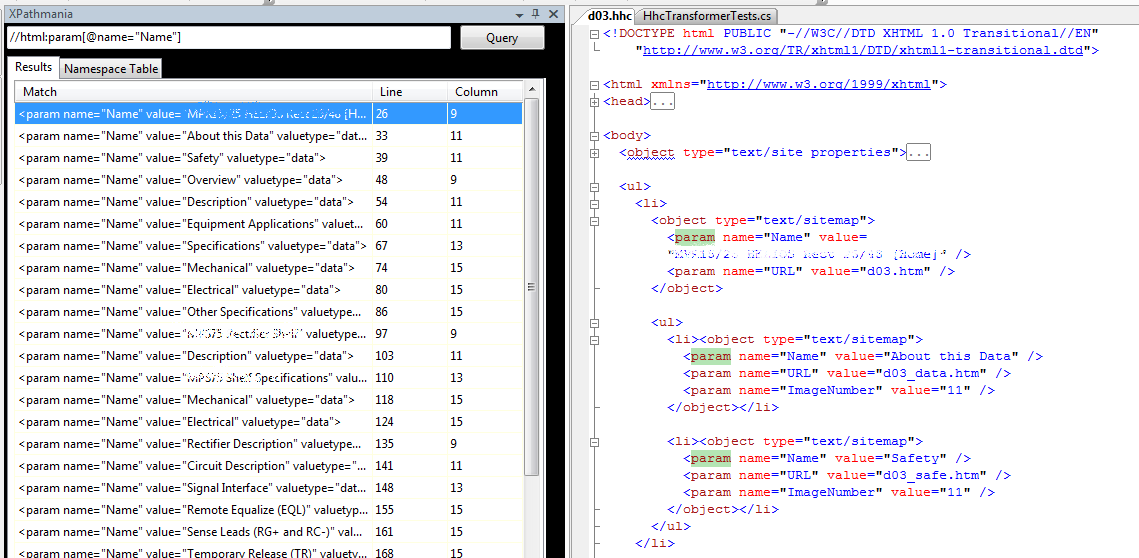
I’m working on building a converter to take a hand-crafted table of contents in HTML and transform it into an XML structure I’ll use for navigation in an app. The input HTML is currently used by an ActiveX plugin (barf) which displays the navigation tree. The HTML’s format is basically this form:
<html>
(cruft elided here)
<head>
</head>
<body>
<object type="text/site properties">
(cruft elided here)
</object>
<ul>
<li>
<object type="text/sitemap">
(cruft elided here)
</object>
<ul>
<li>
<object type="text/sitemap">
(cruft elided here)
</object>
</li>
<li>
<object type="text/sitemap">
(cruft elided here)
</object>
</li>
</ul>
</li>
(NOTE: I’ve used Tidy to first transform the straight, unbalanced HTML into well-formed XHTML. That way I’m able to load it up in an XmlDocument object and do all kinds of tomfoolery with it.)
The tree works via unordered list and list items, with the actual entries being the <object> elements. (They hold navigation and title info which I’ve elided for brevity’s sake.) An object doesn’t have its children as direct decendants of its element, however. Instead, they’re decendants of the sibling <li> element. I need to go through this entire psuedo-tree and pull out and transform the contents of each <object> into a new file where those elements become <TocEntry> elems and children. The target output will look something like this
<Toc>
<BookId>d03.xml</BookId>
<TocEntry>
<Title>Operations Manual</Title>
<Target>d03.xml</Target>
<Id>1</Id>
<ParentId>-1</ParentId>
</TocEntry>
<TocEntry>
<Title>Overview</Title>
<Target>d0300000.xml</Target>
<Id>2</Id>
<ParentId>1</ParentId>
</TocEntry>
<TocEntry>
<Title>Operation Course Manual (top level)</Title>
<Target>d0310001.xml</Target>
<Id>3</Id>
<ParentId>2</ParentId>
</TocEntry>
As part of that transformation I need to assign each <TocEntry> a unique ID. I also need to do some “interesting” XPath navigation to go back up two levels and then to the previous element in order to find the current <object> element’s logical parent.
Walking the input XHTML tree starts by first selecting the top level of the tree, the html/body/ul element. I’ll be using an XPathNavigator object and an accompanying XmlNamespaceManager. The manager will deal with the default namespace for the XHTML document.
NameTable nTable = new NameTable();
XmlNamespaceManager manager = new XmlNamespaceManager(nTable);
//get top-most UL as a node
XmlNode currentNode =
input.SelectSingleNode("//html:html/html:body/html:ul", manager);
XPathNavigator currentNodeNav = currentNode.CreateNavigator();
XmlDocument output = CreateOutputDocument();
output = WalkTree(currentNodeNav, depth, output);
Now I can head off and work through the tree.
private XmlDocument WalkTree(XPathNavigator currentNodeNav,
int depth,
XmlDocument output)
{
XPathNavigator inputNav = currentNodeNav.Clone();
if (inputNav.HasChildren)
{
inputNav.MoveToFirstChild();
ProcessNode(inputNav, output, depth);
while (inputNav.MoveToNext())
{
ProcessNode(inputNav, output, depth);
}
}
else
{
while (inputNav.MoveToNext())
{
ProcessNode(inputNav, output, depth);
}
}
return output;
}
I need to do a depth-first walk of the tree in order to build up the parent-child relationships in the easiest order, so the first thing to do is to run down the line of the current node’s children. If it’s a leaf with no kids then we can process it and look to its siblings, otherwise we’ll dive further into the tree. This is hanlded by the ProcessNode method.
private void ProcessNode(XPathNavigator inputNav,
XmlDocument output,
int depth)
{
if (inputNav.Name.Equals("object",
StringComparison.InvariantCultureIgnoreCase))
{
BuildTocEntryNode(output, inputNav, output.DocumentElement, depth);
}
else
{
WalkTree(inputNav, depth + 1, output);
}
}
BuildTocEntryNode just grabs some values from the current input node and creates new elements in the output document in the format I need. It’s omitted for brevity’s sake since it’s just effectively getter kind of cruft and there’s a moderate amount of it.
The cool bit that took me some work was figuring out the parent node’s ID value. The structure I’m building for the output file is a flat format with its heirarchy stored via ID and ParentId elements — this feeds into a Telerik TreeView control I’m using to display the table of contents in the app. I can’t navigate the output file, but I need information from it. The solution I came up with was to get some unique information from the parent in the input file, then use that as a query in the output file to find the right node.
There’s some cruft elided from the following steps, but you’ll get the idea. First I need to clone the navigator at the current node so I can move it around without screwing up my working context:
XPathNavigator parentFinderNav = currentInputNodeNav.Clone();
Now I can move up from the current <object>, past its containing <li> elem, and then over to the previous node which should be the parent <object> elem.
parentFinderNav.MoveToParent();
if (parentFinderNav.Name.Equals("li",
StringComparison.InvariantCultureIgnoreCase))
{
//move up one more, then previous from <li> to <object>
// we decended from
parentFinderNav.MoveToParent();
parentFinderNav.MoveToPrevious();
}
Now I need to grab the target URL, something unique about this parent node.
XPathNavigator targetNav =
parentFinderNav.SelectSingleNode("html:param[@name=\"URL\"]",
manager);
string parentTarget = targetNav.GetAttribute("value", "");
Now I need to go find the corresponding node in the output file, so I’ll get a new navigator from my current output context:
XPathNavigator outputParentFinderNav = currentOutputNodeNav.Clone();
Now here’s the cool XPath query: I need to find an <Id> element whose sibling has the same value as the URL I got from my input object’s parent (parentTarget above). I can use a nifty XPath selection statement to do just that:
"//Id[../Target = \"" + parentTarget + "\"]"
So the complete statements for that look like this:
XPathNavigator idNav =
outputParentFinderNav.SelectSingleNode("//Id[../Target = \"" +
parentTarget +
"\"]",
manager);
string parentId = idNav.Value;
There are undoubtedly improvements which could be made in this code; however, it passed tests and generated the file in the format I needed and all the Id/ParentId values linked up as required. I’m a happy camper. This could also have been done in XSL; however, I needed to get the feature done in a few days and didn’t have the patience to spend working through the unintelligble XSL I’d need to create to get the transform done. If you’re an XSLT ninja who could do all this in eight lines of XSL then good on you, and please write it up and let me know!
This is probably one of the longest posts I’ve ever written, but I had a couple interesting tidbits to share. Hopefully you’ve found it useful……….